
关键词组:VS Code Cline 教程 (VS Code Cline Tutorial), NVIDIA NIM 免费 API (NVIDIA NIM Free API), DeepSeek-R1 部署 (DeepSeek-R1 Deployment), Llama-3.1-Nemotron, AI 编程双模型架构 (Dual-Model AI Coding Architecture), Plan and Act 模式 (Plan and Act Mode)
内容摘要:抛弃单一代码生成模型的局限,本文深度剖析如何在 VS Code 中,利用 NVIDIA 官方提供的海量免费 Token,为 Cline 接入“双脑架构”。由 DeepSeek-R1 负责复杂架构推演,Nemotron 专注极速代码执行。全文干货,直击痛点,彻底压榨 API 算力,构建企业级本地开发自动化工作流。
缘起:为什么我们需要“双脑”AI编程架构?
在日常的代码编写和系统运维中,无论是重构一个老旧的 Java 11 遗留项目,还是临时编写一个处理复杂日志的 Python 脚本,我们对 AI 助手的要求往往是极其苛刻的。单靠一个通用大语言模型(LLM)来处理所有开发环节,越来越显得力不从心。
目前的现状是:擅长深度逻辑推理的模型(比如具备完整思维链能力的 DeepSeek-R1),在处理海量增删改查(CRUD)或单一文件的大段代码吐出时,往往会因为过度思考而拖慢节奏,甚至消耗过多的上下文;而那些输出极快、指令遵循度极高的指令微调模型(如 Llama 系列),在面对跨越多个文件目录、需要极其缜密架构思维的复杂微服务联调时,又容易出现逻辑断层和“幻觉”。
破局之道在于“规划与执行分离”(Plan and Act)。这不仅仅是一个软件功能的切换,更是工程化思想在 AI 辅助开发中的落地。
近期,NVIDIA NIM(NVIDIA Inference Microservices)开放了极其慷慨的免费 API 额度,涵盖了目前地表最强的一批开源与闭源模型。借此东风,我们将通过 VS Code 的明星级 AI 插件 Cline,把 NVIDIA 的算力白嫖到底,打造一个“DeepSeek-R1 做架构大脑 + Llama-3.1-Nemotron-70B 做敲码双手”的完美本地工作流。
核心前置:获取 NVIDIA 官方 API 与底层梳理
在开始配置之前,我们必须明确底层的弹药库来源。NVIDIA NIM 并不是一个简单的套壳网站,它是英伟达为了推广其硬件生态,针对主流模型进行了 TensorRT-LLM 级别的底层算子优化后,对外释放的标准 OpenAI 兼容接口。这意味着它的推理速度和并发处理能力,远超一般的第三方中转站。
关于如何注册 NVIDIA 账号并获取专属的 API Key,具体的保姆级图文流程,请严格参照这篇前置文章完成操作,此处不再赘述:
👉 NVIDIA NIM 免费大模型 API (DeepSeek/Kimi/GLM) 获取与配置全解
当你拿到了一长串以 nvapi- 开头的密钥后,请妥善保管。该密钥仅在你的本地机器中调用,不会经过 Cline 的云端,物理层面上保证了你的代码资产安全。
深度实战:Cline 双模型架构配置图文指南
打开你的 VS Code,进入 Cline 的设置(Settings)界面。我们将彻底抛弃默认的单模型全局跑法,进入高阶的资源调度模式。
第一步:开启“双脑”路由机制
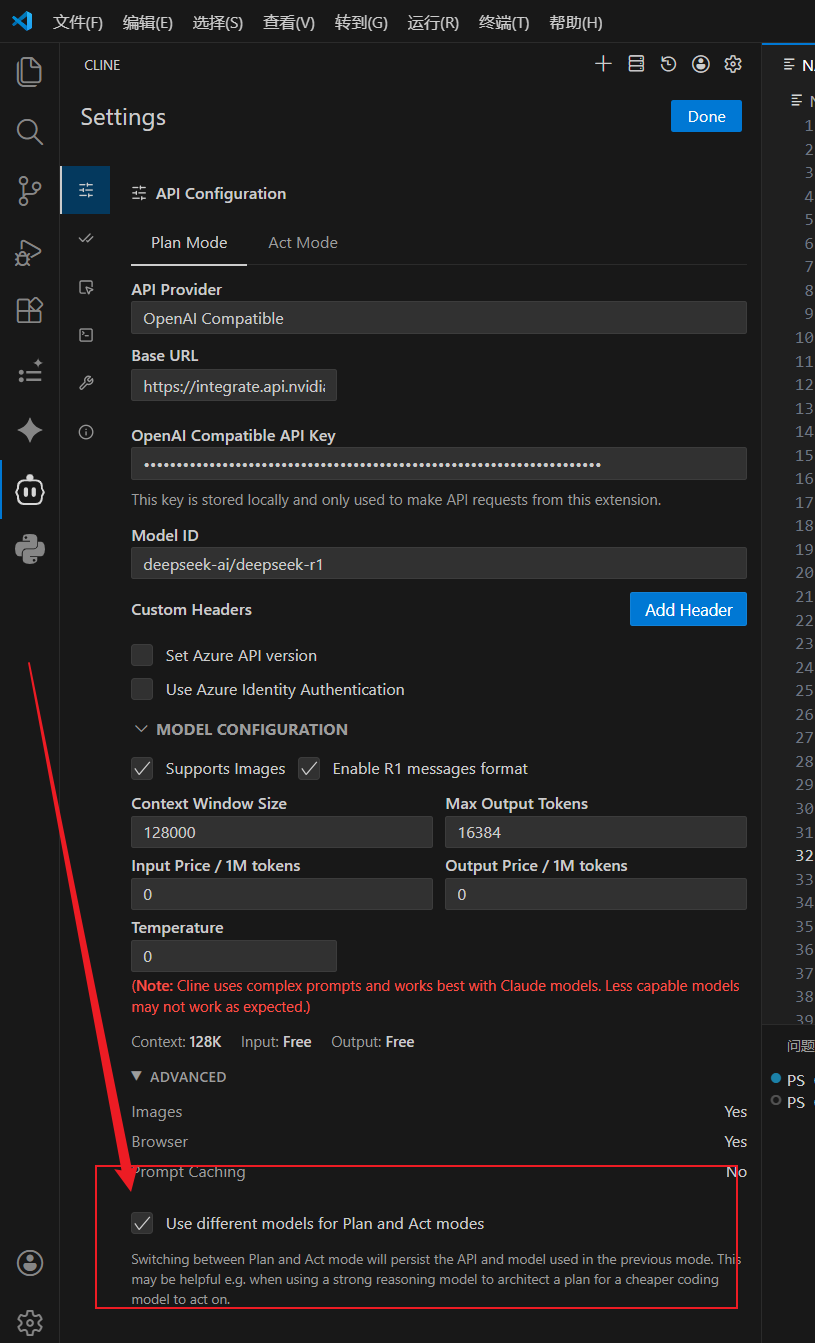
向下滚动 Cline 的设置面板,找到最底部的 ADVANCED(高级选项) 区域。
核心操作:
务必勾选 Use different models for Plan and Act modes(为规划和执行模式使用不同的模型)。
技术原理解析:
一旦勾选此项,Cline 就不再是一个单纯的“问答机器人”,而变成了一个具备多智能体(Multi-Agent)雏形的系统。在处理你的复杂指令时,它会先调用 Plan Mode(规划模式)的模型去阅读你的整个工程目录结构,梳理依赖关系,并生成一份 Markdown 格式的执行蓝图(Plan);确认无误后,再将这份蓝图移交给 Act Mode(执行模式)的模型,由后者飞速完成具体文件的创建、代码写入和终端命令的执行。
第二步:调教 Plan Mode (架构规划大脑)
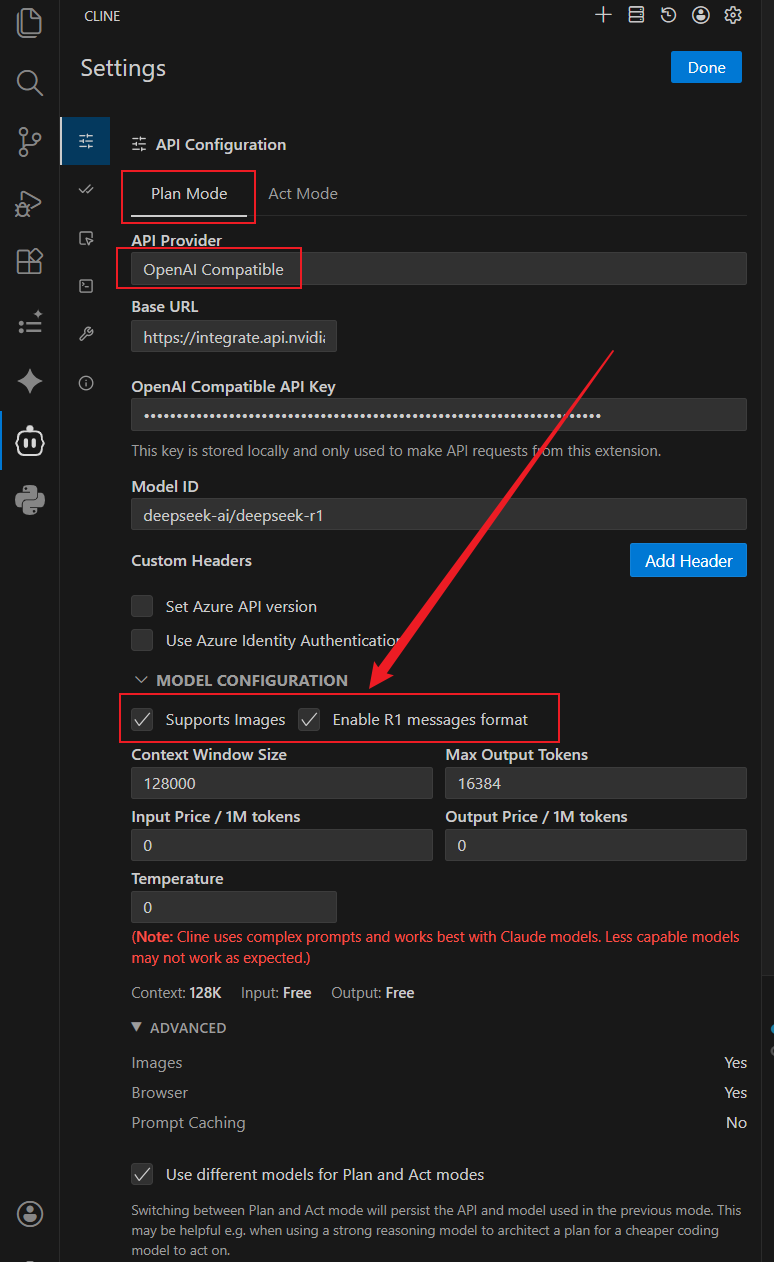
在页面顶部的选项卡中,点击进入 Plan Mode。这里我们需要部署当前逻辑推理的顶流——DeepSeek-R1。它在编写代码前,会在后台进行大量的试错推演(即 <think> 标签内的内容),这对于排查深层次 Bug 或设计项目骨架至关重要。
配置参数精讲:
API Provider(API 提供商): 选择
OpenAI Compatible(OpenAI 兼容协议)。Base URL(基础请求地址): 必须精准填入
https://integrate.api.nvidia.com/v1。注意末尾的/v1绝不可省略,这是标准协议的端点。OpenAI Compatible API Key: 填入你获取的
nvapi-密钥。Model ID(模型标识符): 填入
deepseek-ai/deepseek-r1。请注意全小写及横杠的准确性,这是 NVIDIA 服务器进行路由匹配的唯一凭证。Context Window Size(上下文窗口大小): 填写
128000。深度剖析: R1 模型的原生设计支持极长的上下文。128K 意味着你可以让 Cline 毫无压力地读取数十个几千行的 Java 类文件或庞大的系统日志,而不会发生失忆。
Max Output Tokens(最大输出词元): 填写
16384。深度剖析: 这是至关重要的一点。R1 模型带有思维链机制,其推演过程(内部对话)极其消耗输出配额。如果设置过低(如默认的 4096),极易导致模型在思考复杂系统架构时被强制掐断(Truncation),直接引发 API 报错中断。
Temperature(温度值): 锁定为
0。深度剖析: Temperature 决定了模型输出分布的随机性。在文艺创作中我们需要高温度,但在严谨的代码工程中,我们需要 100% 的确定性。设置为 0 可以强制收敛概率分布,防止模型在生成变量名或调用系统 API 时“自由发挥”引发编译错误。
Enable R1 messages format(启用 R1 消息格式): 必须勾选 ✔️。
避坑提示: DeepSeek-R1 的底层输出结构与传统模型不同,它将思考过程封装在闭合标签内。如果未勾选,Cline 的解析器将无法正确剥离思维链,导致后续传入执行环节的上下文被大量废话污染。
第三步:打磨 Act Mode (代码执行双手)
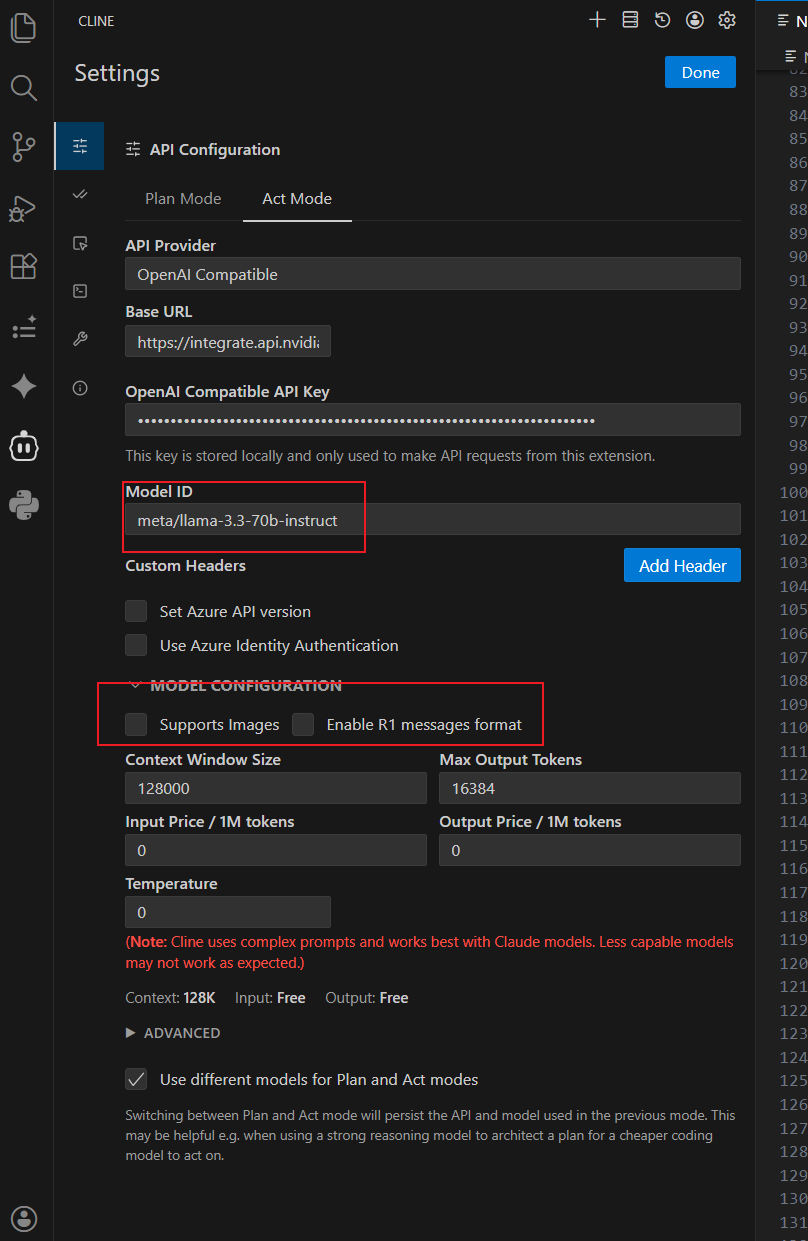
切换到 Act Mode 选项卡。执行阶段不需要复杂的思辨,我们需要的是极致的速度、对指令的绝对服从,以及极其规范的代码排版能力。NVIDIA 官方基于 Llama 3.1 深度微调的 Nemotron 版本是绝佳选择。
配置参数精讲:
Model ID: 填入
meta/llama-3.3-70b-instruct。特性解读: Nemotron 是英伟达专门针对人类偏好对齐(RLHF)进行了大幅优化的版本,废话极少。它不会像一些开源模型那样在给出代码前强行寒暄,而是直接给出可执行的修改块(Diff),这与 Cline 的自动化修改文件机制简直是天作之合。
Context Window Size: 保持
128000。Max Output Tokens: 保持
16384。操作建议: 我们的原则是“严禁代码省略,必须输出全量代码”。在面对重构超大文件时,单次输出庞大。如果未来在实际执行中遇到 NVIDIA 接口返回
400 Bad Request,说明触碰了当时的后端动态负载上限,此时可将其阶梯下调至8192或4096。
Temperature: 依然锁定为
0。Enable R1 messages format: 必须取消勾选 ❌。
避坑提示: Nemotron 属于标准的指令遵循模型,不存在
<think>标签。如果在这里误勾选,Cline 会用错误的正则逻辑去截取其输出,导致代码直接丢失。
Supports Images(支持图像): 必须取消勾选 ❌。
致命错误预警: 这是一个极易踩坑的重灾区。Nemotron 是一个纯文本(Text-only)大模型,没有视觉(Vision)处理能力。如果你保持勾选,当 Cline 尝试调用浏览器抓取网页截图或你主动提供报错截图时,Cline 会将庞大的 Base64 图像数据直接甩给 NVIDIA 的纯文本 API。这会瞬间导致请求崩溃,打断整个自动化流。取消勾选后,Cline 就会“有自知之明”地采用纯文本或 DOM 结构去理解界面,保证工作流坚如磐石。
第四步:清理历史遗留的“毒药”参数
在许多初次配置的案例中,最容易导致 400 报错的就是 HTTP 请求头(Headers)的污染。
终极审查:
检查 Plan 和 Act 两个模式界面中的 Custom Headers(自定义请求头)区域。确保该区域是完全空白的。
很多新手在从其他 API(如 Moonshot 等)迁移过来时,会误将之前的模型名遗留在 Header 的键值对中。发送携带非法 Key 的非标准 Header 给 NVIDIA 严格的 API 网关,会被瞬间拦截。如果看到任何残留,请无情点击 Remove 按钮清理干净。
降维打击:如何写出榨干双模型潜力的 Prompt
配置完成只是拥有了神兵利器,真正决定产出质量的是你作为“指挥官”的提示词(Prompt)功底。在使用双模型架构时,由于 Plan 模型需要进行宏观调度,你必须在初始指令中提供绝对清晰的环境边界。
典型的反面教材(极易产生幻觉的口语化指令):
“帮我写个脚本,把这个目录下的图片处理一下,做个去重,顺便压个缩。”
技术前驱级标准指令模板(融入环境预判与严格约束):
Markdown
# 任务目标:
编写一个 Python 图片去重与压缩自动化工具。
# 当前环境栈预声明:
- 操作系统:Windows 11
- 执行终端:PowerShell
- 核心语言:Python 3.14 (已安装并配置环境变量)
- 图像处理库约束:强制使用标准库或主流兼容库,若需第三方库请在执行前主动询问。
# 详细逻辑与步骤要求:
1. 【环境判定】先检查目录下是否存在测试文件,若无则先生成几个临时测试用例。
2. 【核心逻辑】遍历指定目录,通过计算文件哈希值(如 SHA-256)进行精确去重,严禁仅通过文件名判断。
3. 【数据处理】将冗余文件移动到专门的 `_duplicates_backup` 目录,而非直接删除(防御性编程)。
4. 【输出规范】严禁省略任何代码块。代码必须包含详尽的中文注释,解释哈希去重的核心逻辑。
# 执行模式约束:
请仔细规划目录结构,确认安全后再执行具体的文件读写操作。
当这段指令喂给 Cline 后,深藏背后的工作流是这样的:
DeepSeek-R1 (Plan) 开始思考:环境是 Win11/Python 3.14,必须注意 PowerShell 的路径转义问题。去重用 SHA-256 最稳妥。需要先写个检测环境的探测器。思考完毕,吐出一份多步骤的 markdown 执行计划。
Nemotron-70B (Act) 接管计划:不废话,直接调用 Cline 的文件创建工具,唰唰唰写下完整、带中文注释的高质量 Python 脚本,并自动在终端执行试运行。
这种体验,完全等同于你拥有了一个不知疲倦、不会抱怨的资深架构师和一个手速惊人的高级研发外包。
运维专家的主观避坑总结
经过长时间的折腾和实战打磨,关于这套方案,有几句掏心窝子的经验总结:
不要盲目崇拜单一模型。 试图让一个模型兼顾极度发散的创造力和绝对严谨的代码执行,在当前的技术世代是不现实的。解耦才是王道。
API 连通性测试。 NVIDIA NIM 设在海外,确保你的本地开发环境的网络出口(尤其是终端和 VS Code 本身的代理设置)是通畅的,否则 Cline 会一直卡在转圈状态。
警惕上下文爆炸。 128K 的上下文虽然很大,但每次对话都会累加。当 Cline 在一个任务中连续修改了几十次文件后,底层的上下文树会变得极其臃肿,导致响应变慢甚至报错。养成好习惯:一个核心需求完成后,果断点击清除对话历史,开启新的 Session。 新的任务,从零开始读取当前代码状态,才是最清爽、最稳妥的做法。
快速参考附录
核心配置清单对照表
全局通用参数:Temperature = 0;Base URL 必须以 /v1 结尾;禁止任何自定义 Custom Headers。
参考文献与扩展阅读
Cline 官方双模型架构 (Plan/Act) 设计白皮书与版本更新日志记录。
DeepSeek-R1 官方技术文档:关于思维链输出机制的解析。
版权声明:本文首发于E路领航(blog.oool.cc),转载请注明出处。