
关键词组:大模型 API, Nvidia NIM 教程, 免费 DeepSeek API, Kimi k2.5 接入, GLM 4.7 部署, Python 3.14 LLM 调用, Free LLM API, Nvidia Inference Microservices
内容摘要:大模型 API 调用成本高昂?本文详细拆解如何利用 Nvidia NIM 平台,零成本白嫖包含 DeepSeek-v3.2、Kimi-k2.5、GLM-4.7 等顶级开源大模型的 API。涵盖从账户注册、防封禁策略,到 Python 3.14 生产级代码接入及商业化落地指南,专为运维与独立开发者打造。
楔子:为何我们要盯上 Nvidia 的“免费午餐”?
在实际的业务开发和项目推进中,大模型 API 的调用开销始终是一座大山。无论你是做简单的内容聚合站,还是构建复杂的商业级 Agent(智能体),一旦跑通业务逻辑进入并发测试阶段,Token 的消耗速度绝对会让你看着账单直冒冷汗。
官方文档往往全英文且晦涩难懂,这对于像我这样英语底子薄、全靠翻译软件硬啃的技术人员来说,极其不友好。经过多方实战摸索与踩坑,我发现英伟达(Nvidia)推出的 NIM(Nvidia Inference Microservices)平台,绝对是目前市面上最稳、最慷慨的“羊毛”。
老黄(黄仁勋)在这个平台上不仅放出了当前最能打的一批国产与国际顶级开源模型,更关键的是,它提供了高达 40 RPM(每分钟请求次数)的免费额度。千万别小看这个 40 RPM,国内不少平台标榜 1500 RPM,但在实际生产环境的高并发压测下,往往连 15 都撑不到就给你直接掐断(限流)。而英伟达的基础设施极其强悍,实测网络延迟极低,首 Token 响应速度往往在毫秒级别。
这篇文章,我将从一个具有多年运维与低层代码开发经验的视角,手把手带你完成从零到一的接入。没有任何花里胡哨的理论,全是直接能跑在生产环境中的实操干货。
一、 核心模型矩阵解析:我们能调用什么?
在动手之前,先摸清家底。Nvidia NIM 平台上提供的模型并非是那些淘汰的边角料,而是当前开源界的顶流。以下是几个我们日常业务中最常用到的核心模型(均已在实际环境中反复压测):
DeepSeek-v3.2 (Model ID:
deepseek-ai/deepseek-v3.2)业务场景:代码生成、复杂逻辑推理、长文本分析。
实战评价:目前绝对的性价比之王。逻辑推理能力在很多场景下已经可以作为昂贵的商业闭源模型的平替。如果你在做自动化脚本编写的工具,首选它。
Kimi-k2.5 (Model ID:
moonshotai/kimi-k2.5)业务场景:超长上下文处理、财报分析、长篇小说阅读。
实战评价:Kimi 的长文本能力有目共睹,但在英伟达平台上偶尔会出现网络波动导致的响应延迟,建议在代码层做好超时重试机制。
GLM-4.7 (Model ID:
z-ai/glm4.7)业务场景:中文语境适配、本地化问答、政企合规性内容生成。
实战评价:中文理解能力极强,语气自然,非常适合用作客服机器人的底层引擎。
Step-3.5-Flash (Model ID:
stepfun-ai/step-3.5-flash)业务场景:高频、轻量级的对话,要求极速响应的场景。
实战评价:速度极快!实测首 Token 延迟不到 10 毫秒。如果你的业务不需要处理复杂的图片多模态,将其作为消耗 Token 的主力完全没有问题。
Minimax-m2.1 (Model ID:
minimaxai/minimax-m2.1)业务场景:语音交互后端的文本生成、偏向于拟人化社交聊天的场景。
二、 环境前置条件判定与准备工作
在进行任何注册或代码部署之前,请严格对照以下环境要求,避免在后续步骤中浪费时间。
1. 网络环境要求
注册阶段:推荐使用纯净度较高的网络环境。避免使用万人骑的免费代理节点,这会触发 Nvidia 的风险风控,导致无法收到验证码或直接封号。
生产阶段:由于 API 节点位于海外(
https://integrate.api.nvidia.com/v1),强烈建议将你的生产业务部署在海外服务器上以降低网络延迟。如果你在本地进行开发,请确保你的终端拥有顺畅的国际网络访问能力。
2. 账号物料准备
电子邮箱:强烈建议使用 Outlook 或 QQ 邮箱。实测这两个邮箱在接收 Nvidia 的验证邮件时最快,且不容易被误判为垃圾邮件。Gmail 虽然好,但在国内部分网络环境下可能需要额外的代理配置,增加复杂度。
手机号码:准备一个干净的
+86(中国大陆)手机号。Nvidia 严格限制一号一机,如果该号码已经注册过 Nvidia Cloud,将无法接收第二次验证码。
三、 详细图文逻辑步骤:注册与获取 API Key
接下来的步骤请严格按照顺序执行,不要跳过任何细节。
步骤 1:访问官网并初始化登录
打开浏览器,访问 build.nvidia.com。在页面右上角,找到并点击 Login(登录)按钮。 在此处输入你准备好的 Outlook 或 QQ 邮箱,点击 Next(下一步)。
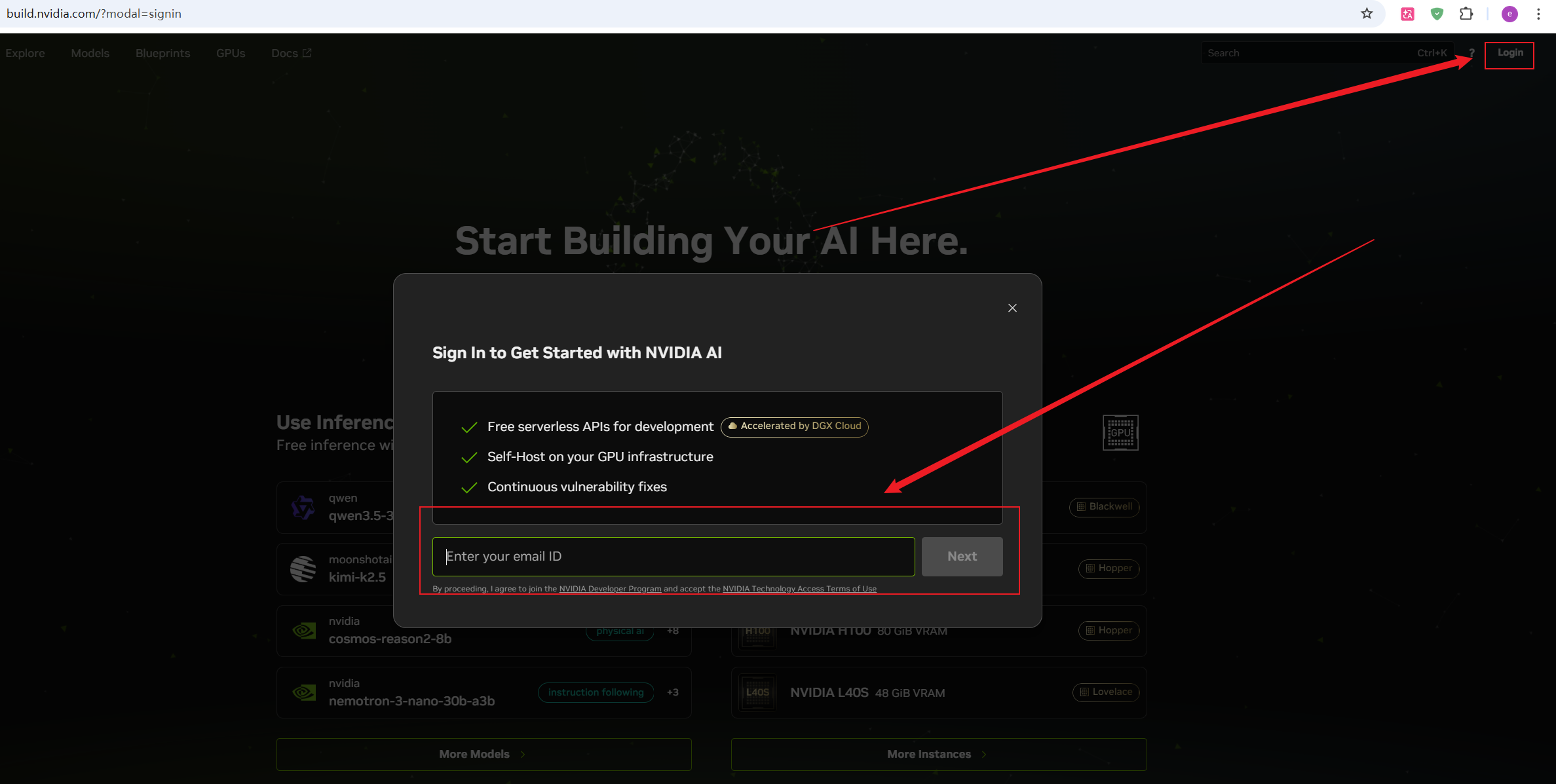
步骤 2:人机验证与账户创建
系统会检测到该邮箱尚未注册,自动跳转至创建账户页面。
首先,勾选“我是人类”进行基础的防爬虫验证。
输入并二次确认你的密码(建议包含大小写字母、数字及特殊符号)。
勾选同意隐私条款。
点击绿色按钮 Create Account(创建账户)。
步骤 3:邮箱激活验证
切换到你的邮箱客户端,你将收到一封来自 Nvidia 的包含多位数字验证码的邮件。将该验证码复制并粘贴回注册页面的输入框中。 注意:如果长时间未收到,请检查“垃圾邮件”或“广告邮件”分类。
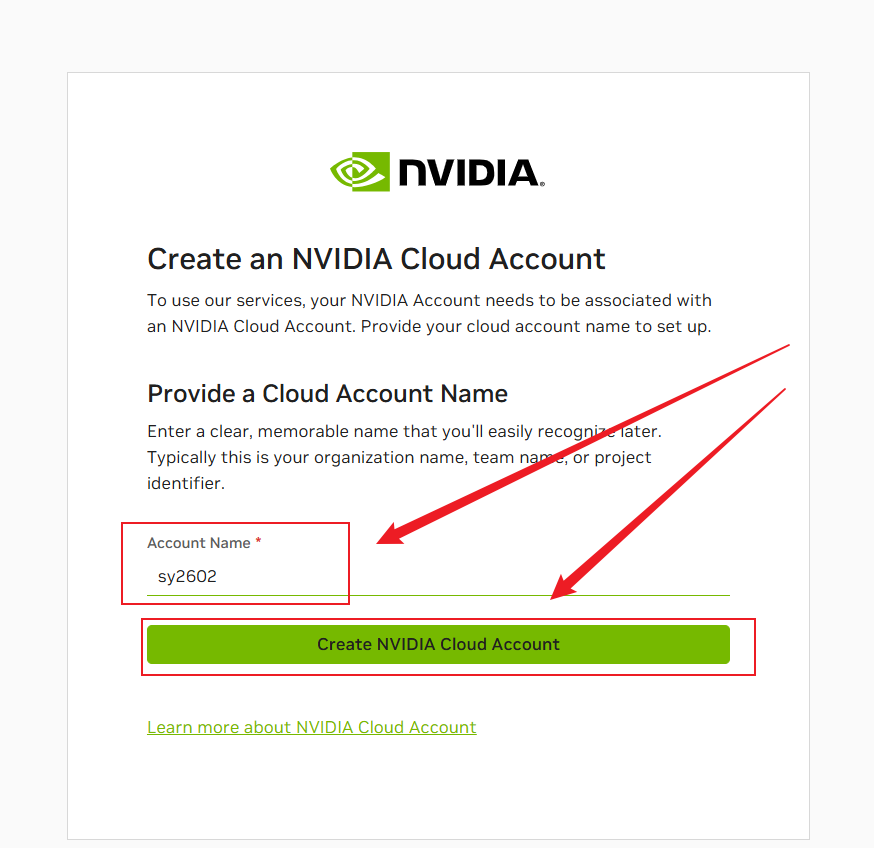
步骤 4:配置 Nvidia Cloud 信息
验证通过后,系统会要求你提供一个“Nvidia Cloud 账户名称”。这里不需要使用真实的商业实体名称,随便填写一个英文字符串即可(例如你的项目代号),方便你自己记忆。 点击 Create Nvidia Cloud Account,页面稍作加载后,会自动重定向回首页。
步骤 5:关键风控点 —— 手机号验证
回到首页后,这是极其关键的一步。在页面的右上角,你会看到一个黄色的或者带有提示性的 Verify(验证)按钮。必须完成这一步,你才能解锁 API 的调用权限和 40 RPM 的高配额度。
点击 Verify 按钮。
在国家/地区代码处,下拉选择或直接输入
+86。填入你的国内手机号码。
点击 Send Code(发送验证码)。
防坑指南:如果点击发送后毫无反应,或者提示发送失败,99% 的概率是因为这个手机号曾经被用于注册过 Nvidia 的其他相关服务(如 GeForce Experience)。此时不要无脑狂点,直接换一个家人或朋友的手机号重试。
步骤 6:生成并保存 API Key
这是整个平台操作的最后一步。
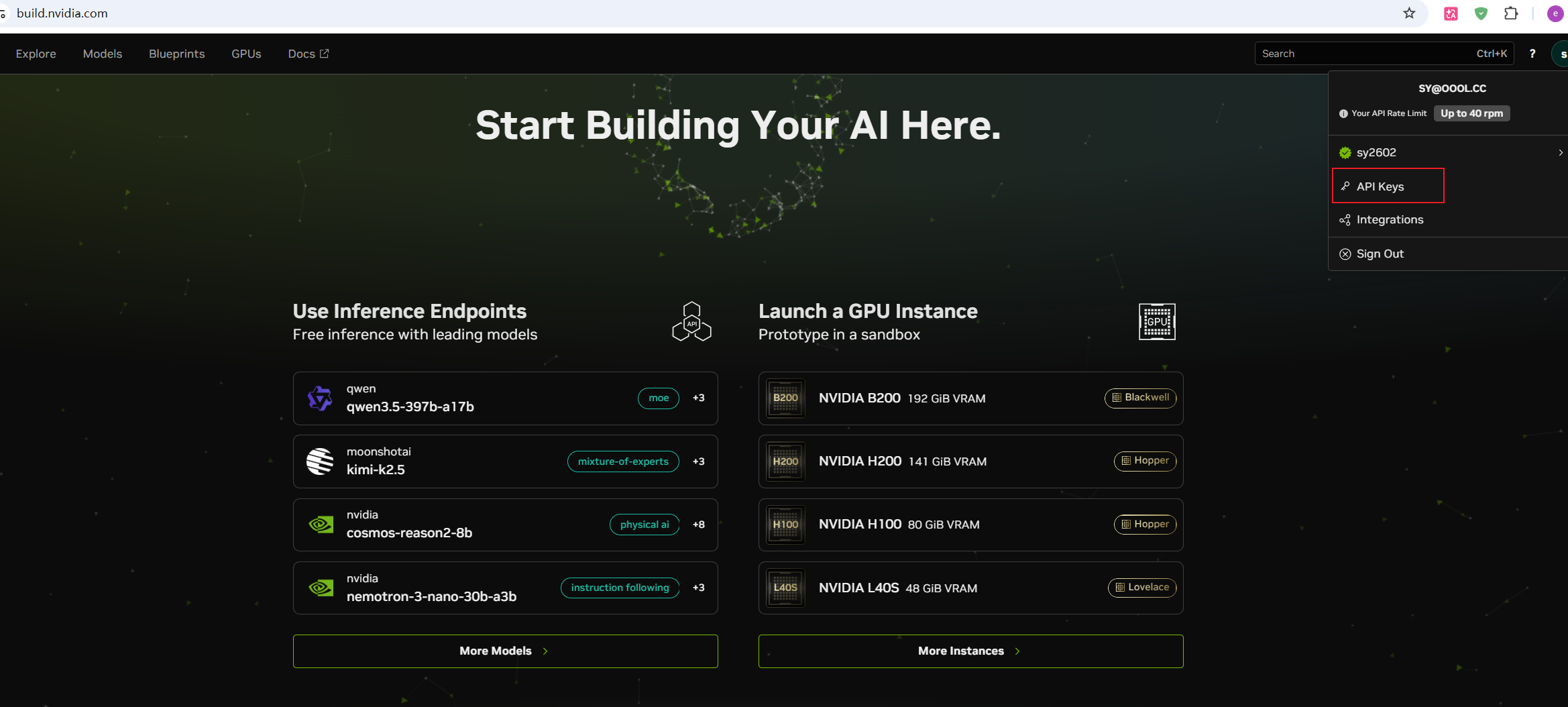
点击右上角你的账户头像(或账户名称),在下拉菜单中选择 API Keys。
在 API 管理界面,点击 Create API Key(创建 API 密钥)。
为这个 Key 命名(例如命名为
dev-test-01),并设置有效期。系统允许的最长有效期为 12 个月(1 年),建议直接拉满。点击生成。核心警告:密钥生成后,页面上会显示一串以
nvapi-开头的长字符串。这个字符串只会显示一次!只会显示一次!只会显示一次! 务必立即将其复制,并妥善保存在你的本地密码管理器或环境变量中。一旦关闭此弹窗,你将无法再次查看该密钥,只能删除重建。
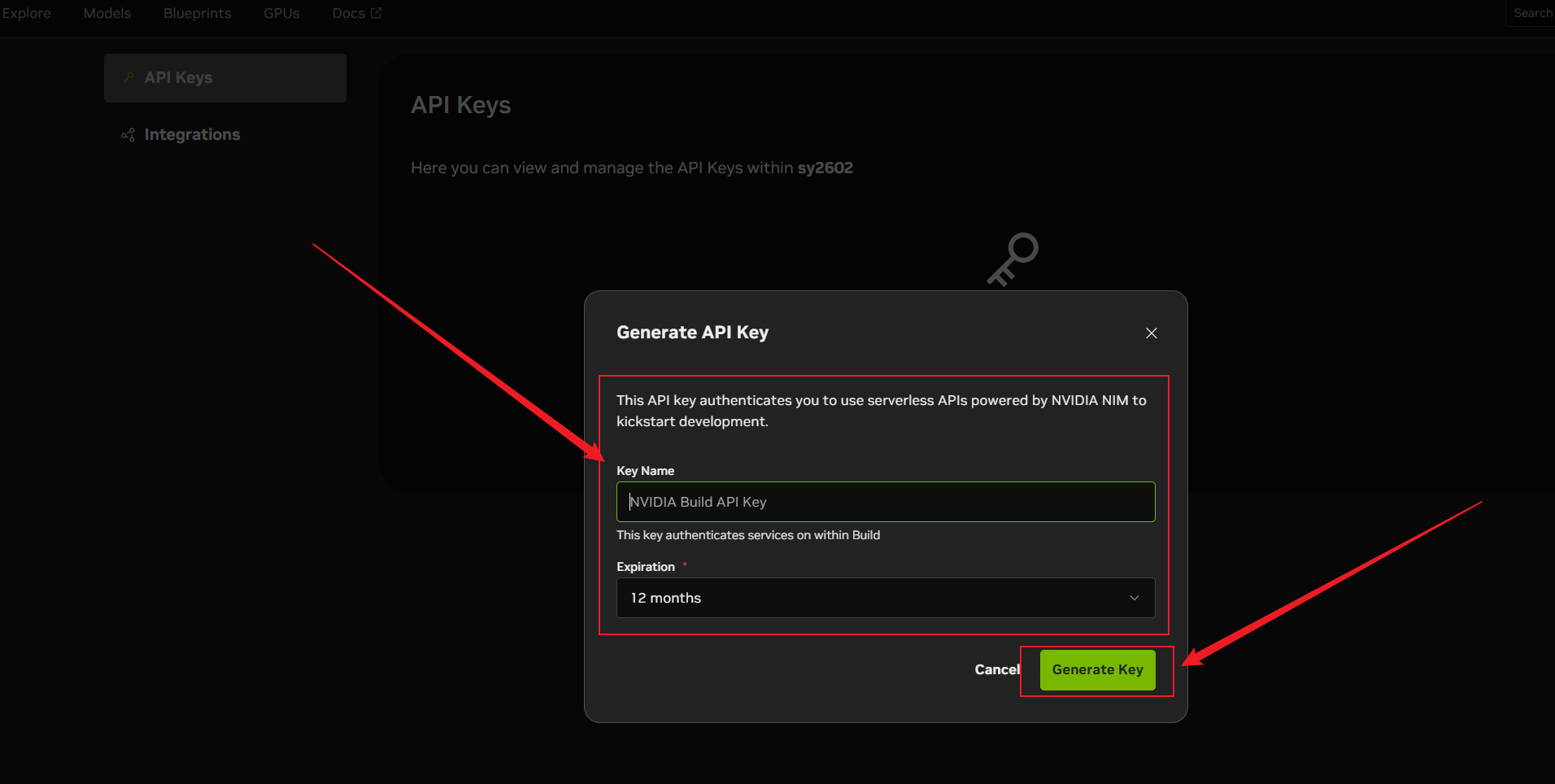
[此处插入一张截图:API Key生成成功后的弹窗,用红色箭头着重标记“仅显示一次”的警告语及复制按钮]
四、 AI 客户端零代码接入实战(以常见客户端为例)
客户端配置请参照:VS Code Cline 结合 NVIDIA 双引擎 (DeepSeek-R1 + Nemotron) 深度调优指南
对于非程序员,或者希望快速测试模型效果的用户,可以将刚才获取的 API 接入到市面上主流的 AI 客户端中(如 Cherry Studio、Chatbox 或 Kelivo)。这里以通用配置逻辑为例进行说明。
打开你的 AI 客户端,进入 设置 (Settings) -> 模型提供商 (Model Providers)。
选择添加自定义 OpenAI 兼容接口(Custom OpenAI API)。
名称:自定义,例如
Nvidia-NIM。API URL (Base URL):严格填写
https://integrate.api.nvidia.com/v1。(部分客户端可能不需要末尾的/v1,请根据客户端官方文档调整,通常完整填写是最稳妥的)。API Key:填入你刚才复制的
nvapi-开头的字符串。自定义模型列表:客户端默认无法获取 Nvidia 的模型列表,你需要手动将前面提到的 Model ID 填入。例如:
stepfun-ai/step-3.5-flash,moonshotai/kimi-k2.5。
配置完成后,保存并点击“测试连接”。当提示连接成功时,你就可以在对话界面无缝切换这些顶级大模型了。
五、 生产环境全量代码实战:基于 Python 3.14 的健壮接入
对于像我一样希望利用这些接口做项目变现的开发者,仅仅在客户端聊天是远远不够的。我们需要通过代码将其集成到我们的业务后端中。
由于英伟达官方的英文文档经常忽略生产环境中常见的网络抖动和限流问题,我为你编写了一套极其健壮的 Python 封装代码。这套代码充分考虑了 40 RPM 的限制,并加入了指数退避重试机制。
1. 环境前置条件
已安装 Python 3.14(向下兼容 Python 3.9+)。
已获取 Nvidia API Key。
终端执行命令安装依赖:
pip install requests。如果是复杂的异步高并发场景,建议使用aiohttp,但为了保持本教程逻辑的透明与精简,我们采用最经典的requests库实现同步调用。
2. 完整代码实现 (nvidia_nim_client.py)
这段代码是全量的,请直接在你的 VS Code 中新建文件并粘贴。关键参数和业务逻辑我都用中文做了详尽的注释。
Python
# nvidia_nim_client.py
# 编码:UTF-8
# 描述:Nvidia NIM 大模型 API 生产级调用封装
# 作者:苏杨 (针对商业化环境优化)
import os
import time
import json
import logging
import requests
from typing import List, Dict, Optional, Any
# ================= 配置日志 =================
# 在生产环境中,日志是排查问题的唯一救命稻草
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ================= 核心类定义 =================
class NvidiaNIMClient:
"""
Nvidia NIM 客户端封装类
支持重试机制、错误捕获,完全兼容 OpenAI 接口规范格式。
"""
def __init__(self, api_key: str = None):
"""
初始化客户端。
强烈建议通过环境变量加载 API Key,严禁将 Key 硬编码在代码中。
"""
self.api_key = api_key or os.getenv("NVIDIA_API_KEY")
if not self.api_key:
raise ValueError("致命错误: 未找到 API Key。请设置环境变量 NVIDIA_API_KEY 或在初始化时传入。")
# 英伟达官方指定的 Base URL
self.base_url = "https://integrate.api.nvidia.com/v1/chat/completions"
# 构造请求头
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
"Accept": "application/json"
}
# 针对 40 RPM 限制设置的安全配置
self.max_retries = 3 # 最大重试次数
self.base_delay = 2.0 # 基础重试延迟(秒)
def chat_completion(
self,
messages: List[Dict[str, str]],
model: str = "deepseek-ai/deepseek-v3.2",
temperature: float = 0.7,
max_tokens: int = 1024
) -> Optional[str]:
"""
发起对话补全请求。
参数说明:
- messages: 消息体列表,标准格式 [{"role": "user", "content": "你好"}]
- model: 调用的模型 ID,默认使用最具性价比的 deepseek-v3.2
- temperature: 采样温度 (0.0-1.0),越高越随机,越低越严谨
- max_tokens: 限制模型输出的最大 token 数量
返回:
- 成功时返回模型的文本回复 (str)
- 失败时返回 None
"""
payload = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"stream": False # 本次教程为了逻辑清晰,暂不使用流式输出(Stream)
}
for attempt in range(self.max_retries):
try:
logger.info(f"正在发起请求 [模型: {model}] (尝试次数: {attempt + 1}/{self.max_retries})")
response = requests.post(
self.base_url,
headers=self.headers,
json=payload,
timeout=30 # 强制设置超时,防止进程永久挂起
)
# HTTP 状态码校验
if response.status_code == 200:
data = response.json()
# 提取并返回核心回复内容
reply_content = data['choices'][0]['message']['content']
logger.info("请求成功,已获取模型回复。")
return reply_content
# 处理被限流 (HTTP 429) - 重点!
elif response.status_code == 429:
logger.warning(f"触发频率限制 (429 Error)。英伟达限制为 40 RPM。")
# 指数退避算法:2秒 -> 4秒 -> 8秒
sleep_time = self.base_delay * (2 attempt)
logger.info(f"等待 {sleep_time} 秒后重试...")
time.sleep(sleep_time)
continue
# 处理其他 HTTP 错误
else:
logger.error(f"HTTP 错误: {response.status_code}")
logger.error(f"响应详情: {response.text}")
break # 非限流错误,直接中断重试
except requests.exceptions.RequestException as e:
logger.error(f"网络连接异常: {str(e)}")
time.sleep(self.base_delay) # 网络波动也稍作等待
logger.error("所有重试均失败,未能获取模型回复。")
return None
# ================= 使用示例 =================
if __name__ == "__main__":
# 模拟从环境变量读取 API Key 进行安全部署
# 实际部署前请执行: export NVIDIA_API_KEY="你的nvapi-密钥"
# 这里为了演示强制塞入一个测试值,请务必替换!
os.environ["NVIDIA_API_KEY"] = "nvapi-xxxxxxxxxxxxxxxxxxxxxxxx"
# 1. 初始化客户端
try:
nim_client = NvidiaNIMClient()
except Exception as e:
logger.error(e)
exit(1)
# 2. 构造对话逻辑(模拟一个运维排错场景)
system_prompt = "你是一位拥有20年经验的高级Linux运维专家。你的回答需要极其精简、直接给出排错命令,禁止说废话。"
user_question = "我的服务器磁盘空间满了,如何快速定位是哪个大文件占用了空间?"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question}
]
# 3. 执行调用 (这里我们选用响应极快的 Step-3.5-Flash)
print("\n========== 开始请求 Nvidia NIM ==========\n")
start_time = time.time()
result = nim_client.chat_completion(
messages=messages,
model="stepfun-ai/step-3.5-flash",
temperature=0.2 # 排错场景需要准确性,调低温度
)
end_time = time.time()
if result:
print(f"🤖 模型回复:\n{result}\n")
print(f"⏱️ 耗时: {end_time - start_time:.2f} 秒")
else:
print("❌ 请求失败,请检查日志。")
3. 部署与调试步骤
在你的生产力机器(如本地 Win11 PC 的 VS Code 中)创建一个名为
nvidia_nim_client.py的文件。将上述代码完整粘贴进去。
打开终端,将
nvapi-开头的密钥写入环境变量(例如在 PowerShell 中执行$env:NVIDIA_API_KEY="你的真实密钥")。执行
python nvidia_nim_client.py。如果一切顺利,你将在终端看到极具专业性的运维排查命令(通常会涉及
du -sh /*或find命令),并且耗时极短。
OpenClaw 智能体工作流的接入,请使用交互配置命令,选择NVIDIA_API填入API_KEY。
六、 商业可行性分析:如何利用它实现变现?
作为一个自由职业者,技术最终要服务于业务和收益。Nvidia NIM 提供的不仅仅是免费额度,而是一条通往低成本 MVP(最小可行性产品)验证的捷径。这里分享三个利用该接口的商业落地思路:
方案 A:垂类自动化内容生成矩阵 (SEO 站群)
痛点:传统 SEO 站群需要耗费大量资金购买文章,或者使用昂贵的商业 API 生成内容,成本极高。
实施逻辑:利用 Python 爬虫每日抓取特定行业(如“出海电商”、“区域旅游攻略”)的热点长尾词。通过我们刚才编写的
NvidiaNIMClient代码,调用性价比极高的DeepSeek-v3.2模型,配合预设的强逻辑 Prompt(提示词),自动生成高质量的技术评测或行情分析文章。收益点:通过大规模内容收录获取 Google 自然搜索流量,挂载 Google AdSense 或行业联盟 CPS 链接变现。40 RPM 的配额,意味着即使代码每 2 秒生成一篇文章,一天也能产出超过万篇,完全足够支撑一个中型博客矩阵。
方案 B:针对海外小微企业的低成本客服 SaaS
痛点:大量海外独立站卖家无力承担每月数十美元的高级智能客服订阅费。
实施逻辑:使用
GLM-4.7(多语言和逻辑理解能力优异)作为核心引擎。你可以开发一个轻量级的中间件,将商家的商品 FAQ 文档作为系统提示词喂给模型,然后将其封装成一个简单的 Webhook 接口,对接给 WhatsApp Business API 或 Telegram Bot。收益点:向商家收取每月 9.9 美元的基础维护费。只要商家流量不是瞬间爆发式增长,Nvidia 的免费额度足以支撑数十个小型商家的日常客服咨询。这是非常典型的空手套白狼(低运营成本)的 SaaS 模式。
方案 C:自动化数据清洗与标注外包
痛点:很多初创 AI 团队需要对原始语料进行清洗(例如去重、敏感词过滤、情感极性判断),人工成本高,商用 API 又太贵。
实施逻辑:接下这类外包订单,利用
Kimi-k2.5强大的长文本处理能力,编写批量处理脚本。虽然有 40 RPM 的限制,但在云服务器上通过后台守护进程(Daemon) 7x24 小时缓慢且稳定地跑批处理。收益点:赚取纯粹的“信息差”与算力执行费。你付出的仅仅是云服务器的电费和你的脚本开发时间。
七、 避坑与故障排查(Troubleshooting)
在实际部署中,你大概率会遇到以下几种情况,我都帮你总结好了应对策略:
错误:HTTP 401 Unauthorized
诊断:API Key 无效或格式错误。
解决:检查代码中的请求头
Authorization是否正确拼接了Bearer前缀(注意 Bearer 后面有一个空格)。如果确认拼接无误,说明 Key 已被吊销或过期,请回控制台重新生成。
错误:频繁遭遇 HTTP 429 Too Many Requests
诊断:触发了平台的 40 RPM 频率限制。这通常发生在你使用了高并发异步请求时。
解决:切忌使用多线程无限制地向 Nvidia 接口发包。请严格按照我在 Python 代码中提供的“指数退避算法”进行拦截与休眠。在生产业务中,建议引入消息队列(如 Redis List 或 RabbitMQ)对请求进行削峰填谷。
问题:输出内容偶尔被意外截断
诊断:
max_tokens设置过小,或者模型达到了其单次输出的物理极限。解决:将代码中的
max_tokens参数调大(例如设置为 4096)。如果仍然截断,说明是模型的长文本生成逻辑阻断,需要在业务代码中检测finish_reason,如果不是stop,则需要将已输出的内容拼接到 Prompt 中,要求模型“继续”。
业务隐私安全警告
诊断:虽然接口是免费的,但你无法保证免费平台不会保留你的输入数据用于后续的强化学习。
解决:严禁将真实的服务器密码、Token、内网网关地址、数据库连接串直接发给 API! 在调用前,必须在本地代码层面进行脱敏(例如用正则表达式将
mysql://user:password@ip...替换为mysql://[REDACTED])。
八、 快速参考附录 (Cheat Sheet)
为了方便大家日后快速查阅,我将最核心的参数整理如下:
平台入口:
https://build.nvidia.comAPI Base URL:
https://integrate.api.nvidia.com/v1/chat/completions免费额度上限:无限总额度,但受限于
40 RPM(每分钟请求数)的速率。高性价比模型 ID 清单:
deepseek-ai/deepseek-v3.2(代码与逻辑首选)moonshotai/kimi-k2.5(超长文本解析首选)stepfun-ai/step-3.5-flash(要求极低延迟响应时首选)z-ai/glm4.7(中文拟人化交互首选)
参考文献
版权声明:本文首发于E路领航(blog.oool.cc),转载请注明出处。