
关键词组: Cloudflare SEO 优化 (Cloudflare SEO Optimization), 301 重定向配置 (301 Redirect Configuration), WAF 防火墙规则 (WAF Firewall Rules), 爬虫管理 (Bot Management), Google E-E-A-T 准则 (Google E-E-A-T Guidelines)
内容摘要
在当前的全球搜索生态下,Google 对网站的安全性与权威性(E-E-A-T)提出了近乎苛刻的要求。本文将带你深度复盘如何利用 Cloudflare 这一顶级流量网关,通过精准的 301 永久重定向实现权重“无损转移”,并手把手教你配置 WAF 防火墙。我们将重点拆解如何精细化管理爬虫:通过“JS 质询”隔离私有子域名、利用“白名单”放行优质 SEO 机器人、果断“屏蔽”无关地域爬虫,从而优化抓取配额,让有限的服务器资源精准服务于 Google 权重提升。
一、 301 重定向:SEO 权重的“无损接力”
在网站运维中,域名更替或结构调整是常有的事。很多新手容易忽略 301 重定向,导致搜索引擎好不容易积累的信任度(权重)瞬间清空。在 Google E-E-A-T 准则中,保持链接的稳定性是“可靠性”的重要体现。
1. 为什么推荐“通配符模式”?
参考下方的操作界面截图,Cloudflare 提供的通配符模式 (Wildcard Pattern) 是对小白最友好的方案。它不需要你编写复杂的正则代码,只需用星号 * 作为占位符,就能精准地将旧地址的每一个路径“平移”到新地址。
2. 手把手配置:以“全站带 WWW”为例
如果你想让所有访问 yourdomain.com 的流量都永久跳转到 www.yourdomain.com,请参照截图进行如下配置:
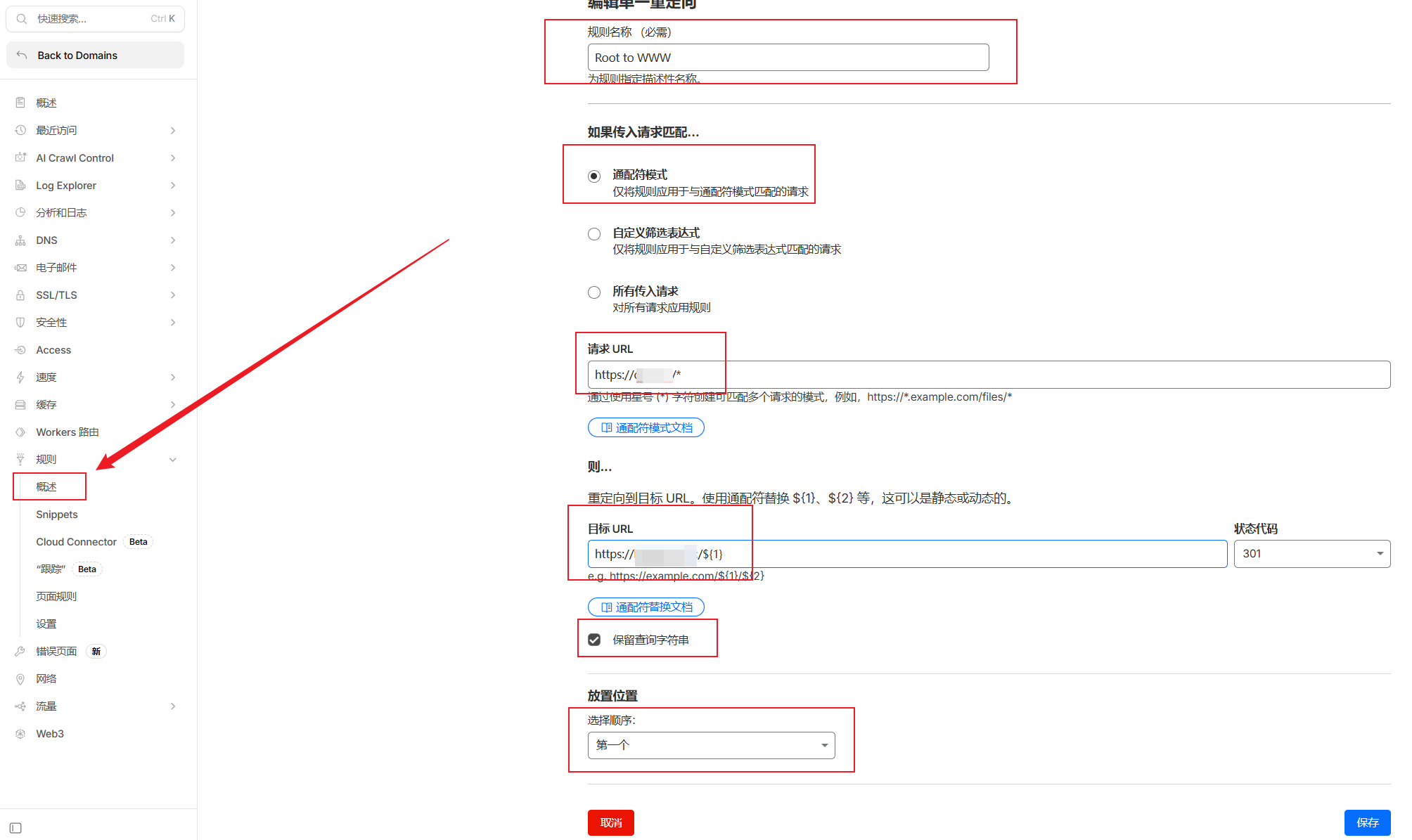
规则名称: 随便起个好记的名字,例如
Global_301_to_WWW。匹配模式: 务必勾选 “通配符模式”。这是最直观的匹配方式,能自动处理复杂的路径转换。
请求 URL: 输入
https://yourdomain.com/*。专家提示: 这里的
*代表你域名后的所有内容(如/about或/post/1),它是抓取旧流量的关键。目标 URL: 输入
https://www.yourdomain.com/${1}。参数解释: 这里的
${1}是一个变量,它会自动填充上面请求 URL 中第一个星号*所匹配到的内容。这样就能保证用户访问domain.com/page-a时,会被精准导向到www.domain.com/page-a。状态代码: 必须选择 301。这告诉 Google 爬虫:这不是临时搬家,而是永久迁移,请把旧页面的 SEO 权重全部传给新页面。
保留查询字符串: 建议勾选。这样即使链接带有广告追踪参数(如
?utm_source=google),跳转后依然能被正常统计。
3. SEO 视角下的 301 价值
权重不流失: 301 能将原有的外链价值 90%-99% 地传递到新 URL,这是 SEO 进阶的必修课。
避免重复内容: 统一入口可以防止搜索引擎同时收录带 www 和不带 www 的版本,避免自己和自己竞争。
极致的用户体验: 哪怕你更换了成百上千个页面路径,只要规则写得对,用户点击旧收藏夹依然能秒开新页面。
二、 WAF 防火墙:从搜索引擎视角看“开门与闭户”
很多站长为了安全,会把防火墙规则设得极其严苛,结果却误伤了 Google 的爬虫,导致收录停滞。在 Cloudflare 的 WAF(Web 应用防火墙)中,我们不玩复杂的代码,直接通过可视化界面就能实现“既安全又利于 SEO”的精细化管理。
按照我们的实战逻辑,WAF 应当分为三层递进防御:私有资产隔离 -> 核心爬虫放行 -> 垃圾流量拦截。
1. 第一道防线:私有子域名的“隐身术”
场景: 你的域名下挂载了 NAS、下载机(BT)或私有后台。这些页面对 SEO 毫无贡献,却容易被爬虫扫到,白白占用你的家庭上行带宽。
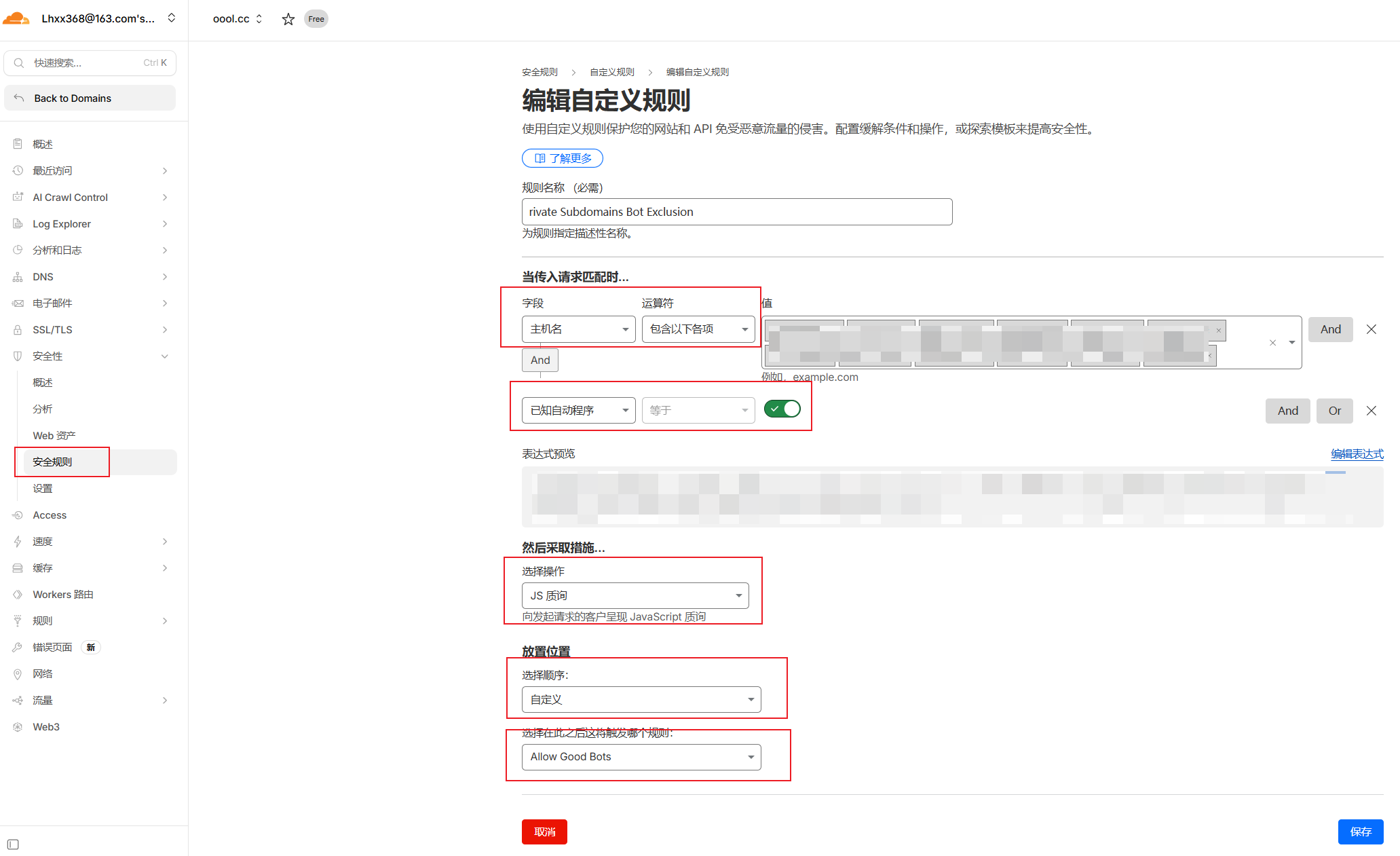
操作步骤:
字段选择“主机名”。
运算符选择“包含”。
值填写你的私有前缀,如
nas.yoursite.com或bt.yoursite.com。操作选择 “JS 质询”。
SEO 深度解析: 为什么不选“阻止”?因为 JS 质询能让真实的浏览器用户通过验证,而 99% 的自动化扫描脚本会被拦截。这样既保护了你的 NAS 隐私,又避免了因返回 403 错误页面导致的搜索引擎惩罚。
2. 第二道防线:给 SEO 贵客发“绿卡”
场景: 我们配置了很多防御规则,但必须确保 Google、Bing 这种“衣食父母”能无视所有障碍,全速抓取你的内容。
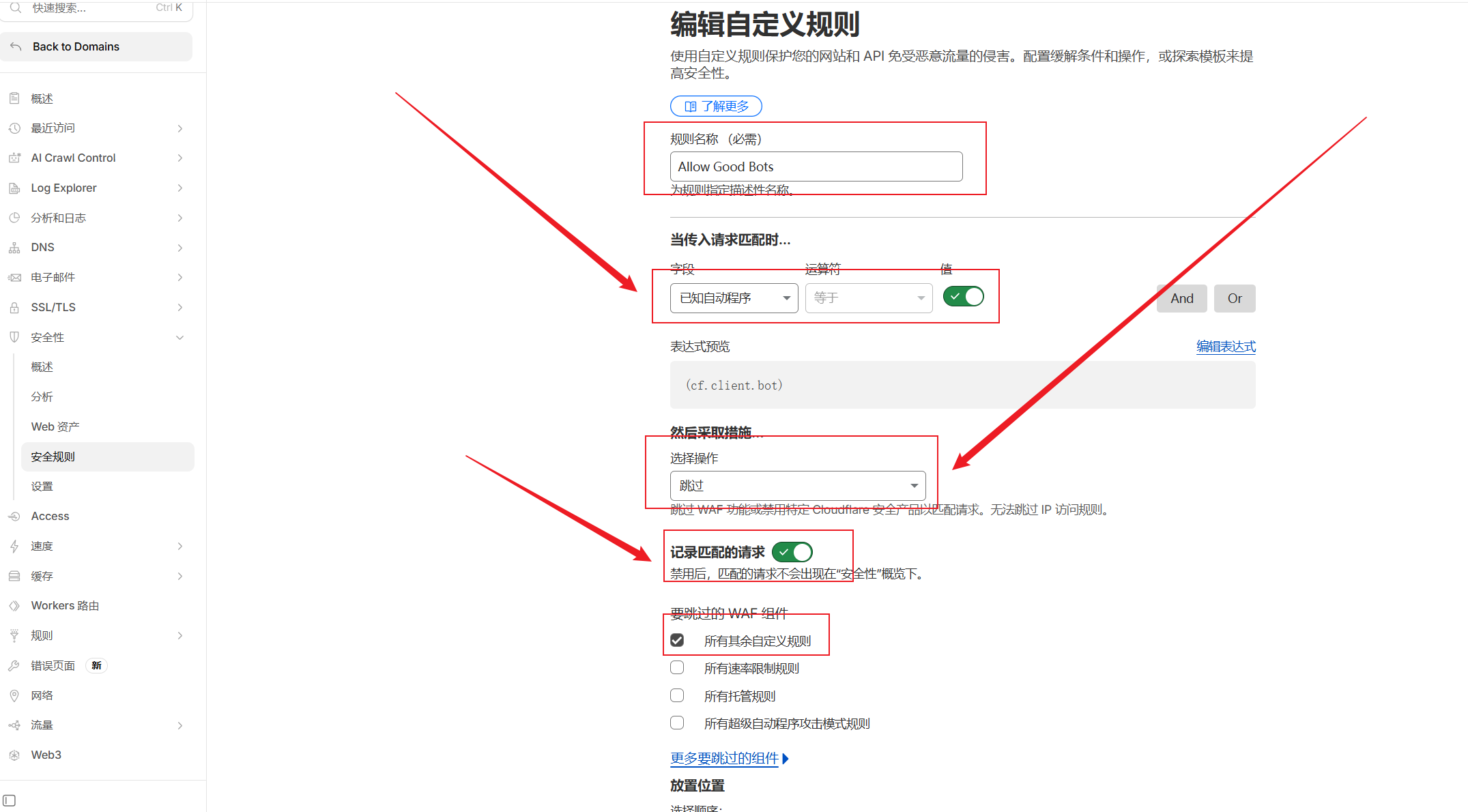
操作步骤:
字段选择“已知自动化程序”。
运算符选择“等于”。
值选择“开”。
操作选择 “跳过”。
勾选所有 WAF 组件,确保它们对 Googlebot 完全放行。
SEO 深度解析: 这是整套体系的灵魂。Cloudflare 官方维护了一份“优质机器人”名单。设置“跳过”后,Google 爬虫访问你的博客就像走 VIP 绿色通道,不经过任何防火墙检测,抓取速度极快,这对提升排名至关重要。
3. 第三道防线:拒绝“无效流量”的无效内耗
场景: 如果你的目标受众是全球或 Google 用户,那么大量来自非目标地区的低质量爬虫(如百度、搜狗)频繁抓取,只会消耗你服务器的性能,拉低网站响应速度。
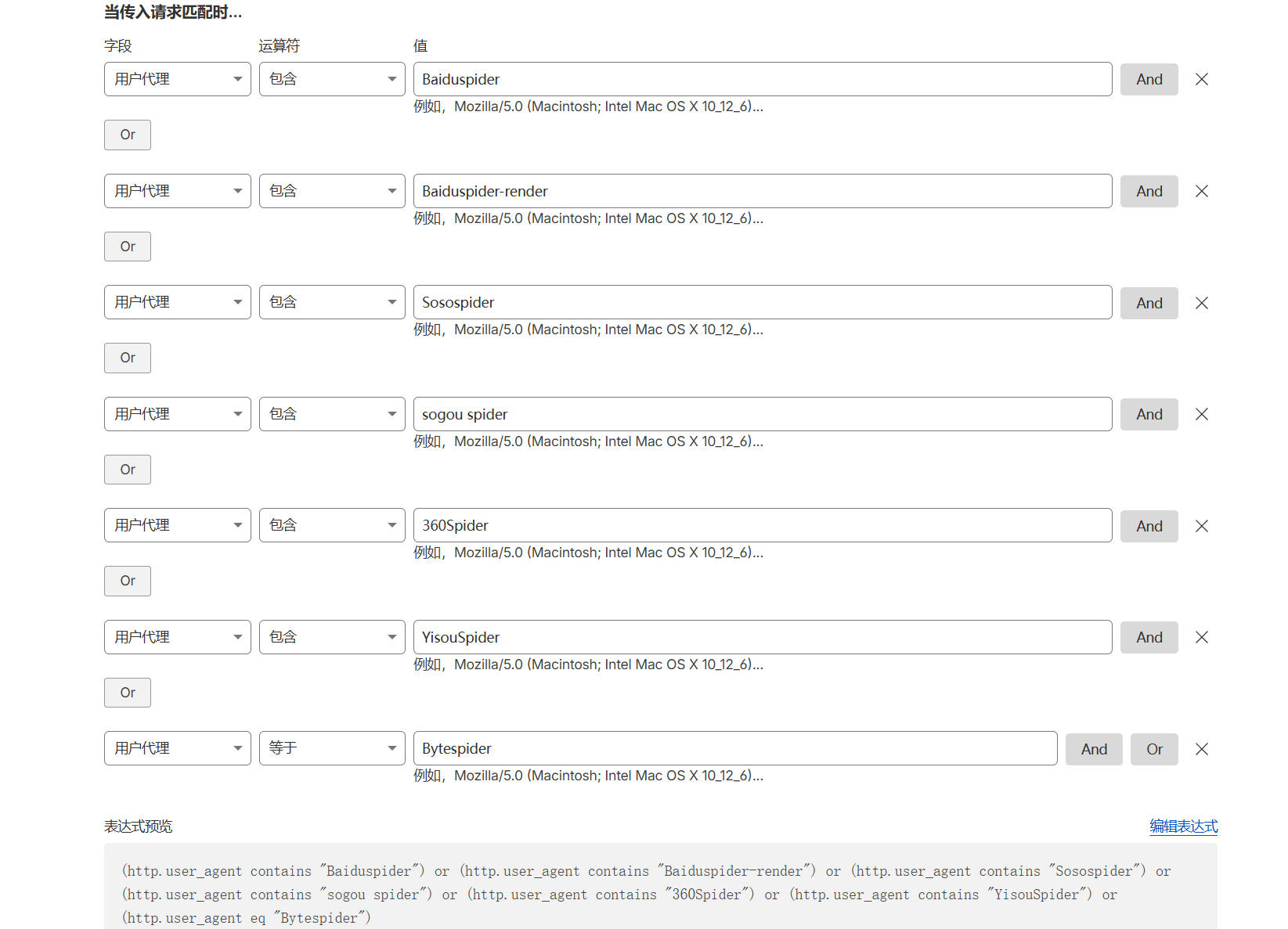
操作步骤:
字段选择“用户代理 (User Agent)”。
运算符选择“包含”。
值填写具体的爬虫指纹,如
Baiduspider或Sogou spider。操作选择 “阻止”。
SEO 深度解析: 响应速度是 Google E-E-A-T 中“用户体验”的核心指标。通过屏蔽这些对你站外 SEO 无意义的爬虫,可以腾出宝贵的服务器资源来服务 Googlebot。记住,抓取额度是有限的,我们要把最好的资源留给最重要的客人。
专家避坑:规则顺序的“致命细节”
在 Cloudflare 的 WAF 列表中,规则是从上往下执行的。请务必核对你的排序:
“Allow Good Bots”必须放在最顶层。(否则 Google 爬虫可能会被后面的规则误伤)。
“Private Subdomains”放在中间。(保护私有资产)。
“Block”类规则放最后。(收尾拦截)。
三、 零基础白话:WAF 规则参数详解
为了方便大家修改,我把最常用的参数整理成了这张“人话对照表”:
四、 技术专家的避坑与优化指南
规则顺序即生命: Cloudflare 规则是从上往下执行的。务必将“跳过已知机器人”放在最前面。如果把“JS 质询”放得太靠前,Googlebot 可能会因为通不过 JS 检测而直接放弃你的网站。
监控 CSR(质询成功率): 在截图中的“CSR”一栏,如果发现数值极高(如 100%),说明你的拦截规则可能太暴力了,误伤了真实用户,需要及时调整。
不要过度依赖插件: 尽量在 Cloudflare 层面解决问题,而不是在服务器里装各种复杂的防火墙插件。越靠近边缘(Edge),性能消耗越低,你的网站加载就越快。
五、 速查附录:一键配置脚本/规则
如果你熟悉 Cloudflare API 或者想要保存这些规则,可以参考以下逻辑(请自行替换占位域名):
Bash
cat << 'EOF' > cf_waf_rules_config.txt
# 规则 1:放行已知优质爬虫 (优先级最高)
(cf.client.bot) -> ACTION: SKIP
# 规则 2:隔离私有资产 (JS 质询)
(http.host in {"nas.yourdomain.com" "bt.yourdomain.com" "dev.yourdomain.com"}) -> ACTION: JS CHALLENGE
# 规则 3:精准拦截无关地区爬虫 (阻止)
(http.user_agent contains "Baiduspider") or (http.user_agent contains "Sogouspider") -> ACTION: BLOCK
# 规则 4:保护管理后台
(http.request.uri.path contains "/admin") and not (ip.src in {你的家庭固定IP}) -> ACTION: BLOCK
EOF
引用文献
隐私脱敏声明: 本文示例中已对所有真实 IP、私有子域名及特定服务器环境进行脱敏处理,相关配置仅供教学参考。
版权脚注: 本文首发于 E路领航 (blog.oool.cc),转载请注明出处。